|
I am an Applied Scientist in Brand Programs at Amazon. I graduated from the University of Texas at Austin with an MS in Computer Science and was a part of the IDEAL Lab! During my masters, I was an Applied Scientist Intern at Amazon Alexa AI over the summer of 2020. Before coming to UT Austin, I completed my undergradtue studies at the National Institute of Technology Karnataka, Surathkal, India where I graduated with a Gold medal. I worked with Dr. Harsha Simhadri and Dr. Prateek Jain at Microsoft Research, India as a part of my undergraduate thesis. I designed a meta-learning algorithm which enables RNNs to make rolling predictions, this reduces the computational complexity and enables it to be deployed on tiny edge devices (as small as 2KB!). I also contibuted to developing resource efficient speech recognition systems, this work is currently under review at NeurIPS 2019. I spent the summer of 2018 in the beautiful city of Heidelberg under the guidance of Prof. Fred Hamprecht (and a huge shout out to Steffen Wolf!). I developed a GAN framework for instance segmentation using the Mutex Watershed algorithm. I spent the summer of 2017 at the amazing IISc where I worked on spiking neural networks. I began my journey into the world of research in the summer of 2016 at IIT Gandhinagar under the guidance of Dr. Shanmuganathan Raman, where I worked on unsupervised object detection. My interests are broadly in machine learning. I have worked on problems in the domains of model compression, distillation, speech recogintion, object detection, image segmentation, resource-constrained machine learning, medical imaging, image retrieval, spiking neural networks, keyword detection in speech, activity recognition and am looking to explore more! |

|
|
|
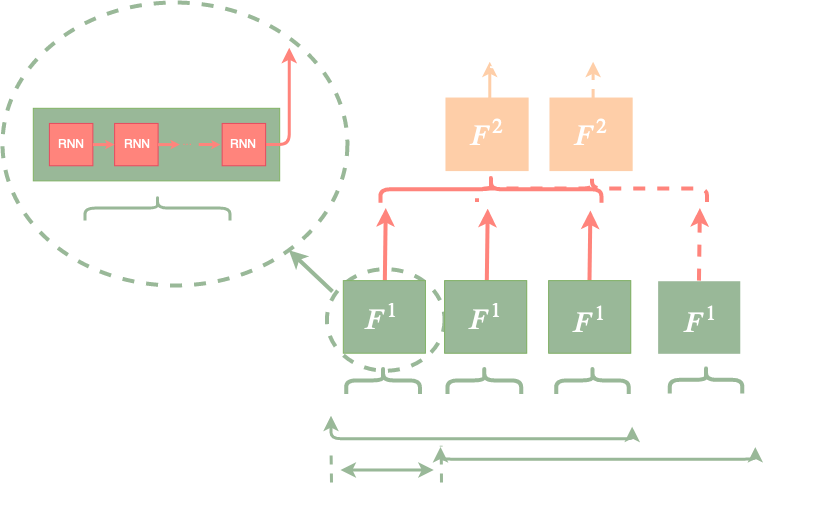
|
Don Don Dennis, Durmus Alp Emre ACAR, Vikram Mandikal, Vinu Sankar Sadasivan, Harsha Vardhan Simhadri, Venkatesh Saligrama, Prateek Jain, Conference on Neural Information Processing Systems (NeurIPS), Vancouver, Canada, 2019(Poster Presentation) [Paper] [Supplemnetal] Recurrent Neural Networks (RNNs) capture long dependencies and context, and 2 hence are the key component of typical sequential data based tasks. However, the sequential nature of RNNs dictates a large inference cost for long sequences even if the hardware supports parallelization. To induce long-term dependencies, and yet admit parallelization, we introduce novel shallow RNNs. In this architecture, the first layer splits the input sequence and runs several independent RNNs. The second layer consumes the output of the first layer using a second RNN thus capturing long dependencies. We provide theoretical justification for our architecture under weak assumptions that we verify on real-world benchmarks. Furthermore, we show that for time-series classification, our technique leads to substantially improved inference time over standard RNNs without compromising accuracy. For example, we can deploy audio-keyword classification on tiny Cortex M4 devices (100MHz processor, 256KB RAM, no DSP available) which was not possible using standard RNN models. Similarly, using SRNN in the popular Listen-Attend-Spell (LAS) architecture for phoneme classification, we can reduce the lag inphoneme classification by 10-12x while maintaining state-of-the-art accuracy.
|
 
|
Mandikal Vikram, Steffen Wolf, Smooth Games Optimization and Machine Learning Workshop, NeurIPS, Montreal, 2018, (Accepted for Spoltlight presentation) [Paper] [Poster] [Slides] [Talk/Video] We propose a GAN loss function along with the supervised loss for training a network to produce affinities for the Mutex Watershed algorithm. We show that this method and additional auxiliary task losses improve the quality of the segmentation. We present an ablation study to show that when the images in the target domain are constrained to be discrete, adding an auxiliary task with smooth target images significantly improves the training performance and stability. |
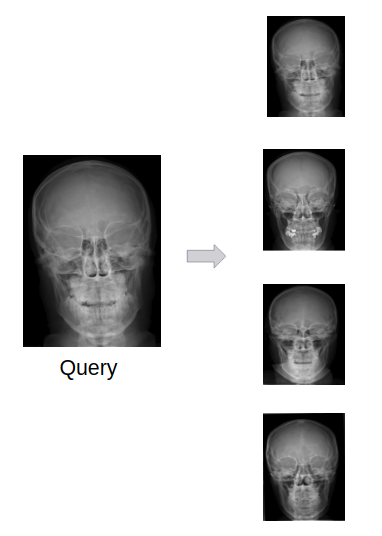
|
Mandikal Vikram, A Aditya, Suhas B S, Sowmya Kamath The ACM India Joint International Conference on Data Science & Management of Data (CoDS-COMAD), Kolkata, 2019 (Oral Presentation) [Paper] [Code] A short version is accepted at the AI for Social Good Workshop, NeurIPS, Montreal, 2018! [Paper] [Poster] Latent Dirichlet Allocation (LDA) based technique for encoding the visual features of the medical images along with novel early fusion and late fusion techniques to combine the textual and visual features.
|
|
|
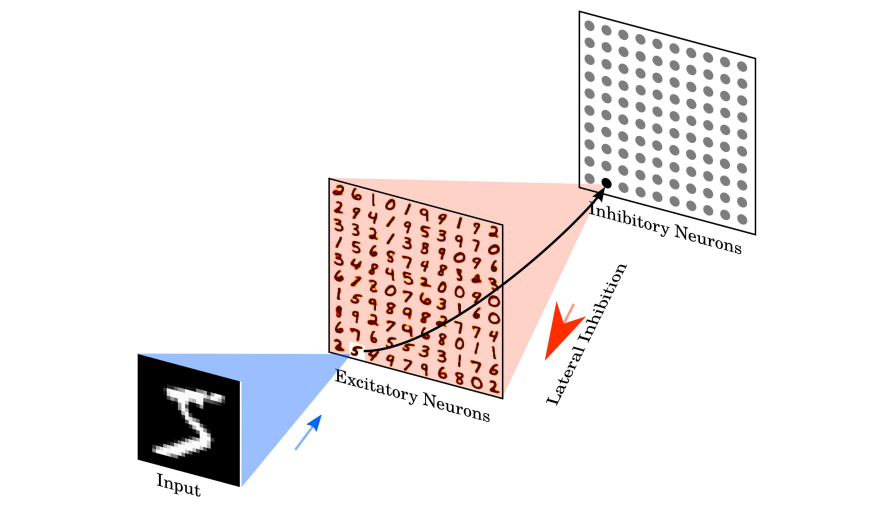 |
|
 |
|
 
|
|

Image Credits: Link |
|